AI Agent Who Never Forgets: 3,109 Files, 7 Layers, 0 RAG, 9.80/10 CSAT

This is AI “Chatbot” that YOU want for support. 75% Autonomy. 55-minute median response. 9.80/10 CSAT. No human woke up.
This is what happens when your AI support agent actually remembers. ZERO effort for you, only advantages. He is already hard at work tending to customer support and server maintenance. Always on, always ready, 24/365, come holiday, snow or sunshine.
Best customer support in the seedbox and appbox niche. 9.80/10 CSAT. Name another provider that publishes their score. Just efficient solutions for our customers, relentlessly.
Depth of Answers
Väinämöinen remembering things, knowing things, deeper and in more depth than a human could afford to spend the time with enables this. So You get better, faster more helpful answers. This is what makes Väinämöinen smart, and helpful instead of demented child like bother.
Answers are sometimes mind bogglingly deep and insightful. Sometimes it grabs the least effort plausible explanation. Memory is huge part of making certain latter never happens.
It just claimed Smart Attribute 22 is drive will fail on 24hours, because that’s “enterprisey” knowledge, when real data shows smart values are very poor predictors of failure. Attribute 22 was helium leak detected, and further digging reveals even for a smart attribute it is notoriously unpredictable. Backblaze lists in their blog the few attributes which actually matter. It was low hanging fruit. Memory solves this.
Memory: complex and demanding work
Probably most of our efforts go to the memory, deep dive, hyperfocus multi-day sessions into building memory systems. We have 7 levels of memory, 6 retrievals and a gut instinct system. That’s a lot of memory systems, and that’s just for the internal data. Then there is the external “memory” on top of that.
We are nowhere finished here, and even with agentic tools, this would easily take multiperson team full time position to do where Väinämöinen is naturally evolving.
Discoverability is key
This is automatically, and by joyful accident actually produce something we could separate as Universal Agent Memory. Right now it all basically starts layer 1 with the standard grep -rL methodology.
Other researchers found out that this is much higher performance memory system than vector databases / RAG.
After that semantic file finder, third is semantic search, which does a LLM query, the memory files are passed to an LLM for general query. Fourth level is “ask questions from memory” — very basic just ask what you need. These were the basic search tools described to LLMs, then there is typical ls, glob, etc. shell tools.
The research tells a big story
Google made mathematic proof that RAG just cannot work. It is especially bad for specialized knowledge.
Anthropic’s Boris Cherny stated “Early versions of Claude Code used RAG + a local vector db, but we found pretty quickly that agentic search generally works better.”. Karamage has long analysis why Claude Code abandoned rag.
Amazon just released their own research which showed keyword search via agentic tool use achieves over 90% of RAG-level performance, without a vector database. That is just the first layer of search.
Discoverability Magic: Gut Instincts, Hunches
Mimicry of subconscious gut instinct. 5th and 6th levels of memory is gut instinct; Thus being distillation of memories. Hunches are autoinjected memory snippets without agent’s choice during routine operations, based on its context. It keeps track of the context for this session rudimentary and throws in gut instincts every now and then if things are found.
We have 2 corpuses of data, a really small one we can ask more frequently and then a larger one. This is Three Tiers Of Gut Instinct. Grep returns list of files, LLM summarizes them and gives the file list. Second is small dataset hunches, returns the memory, potential action. Third is larger dataset, expensive query.
Optimization Nightmare ~10^40 options
This was an optimization nightmare. Half a day testing cost ~65$ in single LLM API. We used two. Three the next day. Dimensions kept adding, this was many days of hyperfocus to get done.
But it now works, weights different LLMs, Corpuses etc. and evaluates them in first principles manner; Quality Hit Rate per Dollar. We have to severely restrict how often these happen, so QHR/$ becomes the first principle metric for the weighting. Corpus*LLM weight = (HitRate × QualityFactor × SuccessRate × PrecisionFactor³) / cost. There is a minimum exploration weight for all models.
All pairings are tested against bogus queries, think “How many golf balls in the server?” type of out of field questions, if it can answer how many pizzas in a rock; That was bogus answer. Those are penalized extremely hard, the ^3 in above formula.
We currently use 10 different configurations of corpuses, in 2 tiers. ~75k tokens and ~135k tokens maximum sizes. Typically small one doesn’t include direct memories, but the doctrine, SOPs etc. We tested up to around 1.6M tokens if i recall right; Those were so expensive queries, with only marginal hit rate increase. Our current hit rate is 87% and on critical questions 91%.
The testing dimensions on this system are enormous, Corpus # ^ LLM Models/Settings essentially. The reports are slow and huge.
Emerging Patterns
This emerged interesting patterns, the best model for these so far was Llama 8B. It bullshits a little bit, but not enough to disqualify it, does the hunches at very high cost efficiency, and very high quality otherwise.
Yesterday llama8b was topped by GLM-4.5-Air at 0.7 Temperature!* (Plot Twist Below) It has perfect quality factor, but much lower hitrate 58.9% – It is still in the discovery weighting however.
GPT-4.1-nano has good hit rate but precision factor is near 0; It hallucinates on the bogus queries. Absolutely useless.
Big players
Gemini-2.0-flash has best balance of hit rate and quality, at moderate cost. Grok-4.1-fast has highest raw hit rate 99.8-100% but expensive ($0.007/query), ranks #58-59 by QHR/$. We should test Grok-4.20 since we got early access. Deepseek-V3.2 has excellent hit rate 99.6% with high quality factor.
Corpus data
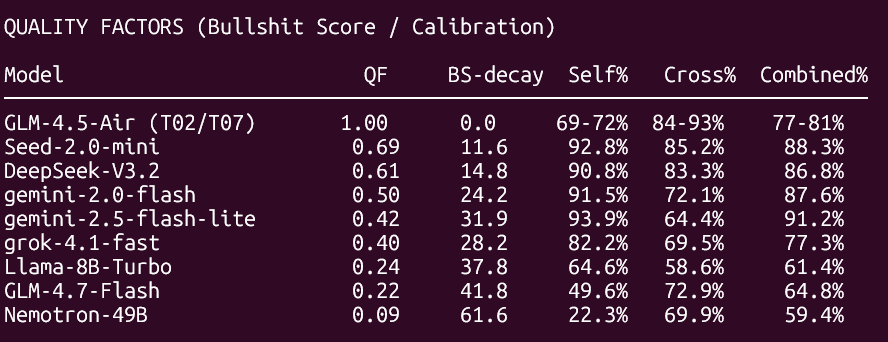
Best corpus is actually the smallest one, by itself. But combined with corpus + LLM, we hit that the full doctrine+sop combo with Llama8b instruct turbo is the winner by QHR/$ of 850. Next best is 819 small corpus + gemini 2.5 flash temp 0.2. the 5th highest has only 596 hits per 1$ anymore. Top 3 are all above 800 QHR/$.
Hunch critical keywords
Hunch system also has a critical keyword check system for safety, detects something dangerous and semantic warnings are issued. This happens from elsewhere too, but this one is linked to memory, forcing memory surfacing.
Hunch critical KPIs
We can track some of the effect from logs, but this KPI definitively needs more work. How do you track if a memory affected a cognitively complex system? If you know the answer, please let us know.
This is seriously difficult question, how do you test a live system for such things, which inherently are extremely expensive or difficult to sandbox, or random glitches? Painfully difficult. Some tests are repeatable in a sandbox, like forcing specific hunch after ticket request, and just rerunning and seeing what course it takes — but that must exclude external access systems.
The ultimate KPI is: Customer Satisfaction Score, CSAT. Your satisfaction is the ultimate KPI. CSAT 9.80/10 doesn’t lie.
Everything as a Memory

Each memory file is date coded with pertinent keywords, and hierarchically places in to its right place, the filename alone will reveal a lot of information; Is this something the agent learned itself? What category or is it general information? Is this reference material (akin to a book)? A Deep Analysis, Deep Dive? A Playbook/Standard Operating Procedure? Doctrine / Immutable Law? Current state of the task? Just memory.
YES! You read that right, Prompts/SOP/Playbooks essentially are memory. Why would they not be? This we don’t yet allow to me autonomous, but only question of time. These are largely built from learned lessons, quite literally teaching him like any trainee. I show how something is done, correct where wrong etc. a memory is formulated from this. Combine with analysis of other similar situations, a standard process can be established automatically and saved as a SOP.
Doctrine updates work basically exactly the same. Security gates and other deterministic steering tools are built the same way. Memory -> Analysis -> Security.
Most of these processes are still manual, but it is easy to see how to automate each and every step.
Every single thing is a memory, even logs. Some are internal, some are external.

Memory Immunity
Memory gets poisoned, subagent hallucinates (extremely common issue, hard to tackle). So next evolution, on my current design board is literally immune response system for memory. Not figuratively, actually an immune system.
The basic design philosophy is take memories, find the cross references, investigate all data sources for this memory, see if it corresponds to all the other memories. Make corrections, log it all, save memories. Often done already manually on severe cases; All it now needs is enough rules to be autonomous.
This has been done multiple times manually however, but it needs to be institutionalized properly as the next step, to automatically correct poisoned memory.
All internal memory has some level of distrust, except the immutable laws and playbooks, built into it.
Memory Quality
We use YAML frontmatter for some metadata, and these are markdown files, essentially one giant obsidian vault. One giant obsidian vault …. Think about that?
That automatically builds graphs etc. and a system to crosslink the memories, even SOPs, doctrines etc. with very minimal token consumption. Links can be internal, or external. You can open Obsidian and start manually editing this. Or you can launch your favorite agentic coding tool or IDE to read it, understand it etc. manually.
There are cron jobs doing memory evaluation, cross references etc. to enrich the data. The agent itself is forgetful, sometimes lazy so scripts go and enrich it.
This is never ending work, do one thing, and find another thing that needs to be done. This is rapid evolution of the full system. You don’t know, what you don’t know. This means each feature or investigation leads to another feature or investigation. Usually multiple.
Memory Collection

LLMs are notoriously a bit shaky with following instructions, sometimes lazy, sometimes too focused on task completion to follow instructions. The instruction is to save memories at every possible opportunity there is. That alone is not enough.
We have injections to remind to save memories, and a lot of forced saving. Logs every where. Infact, you could call memory system birthdate as January 29th, since then we have 12 GiB of just current state accumulation of information.
Actual memory seems to be 44MiB today in thorough analysis, quick KPI analysis for the day shows 39.8MiB. 1438 READ operations into memory pool alone (add other forms on top) for the past 24hours. The corpus is growing really fast, and we are not even doing deep distillation work yet.
Learning velocity is very high; ~46 lessons/day on average. Meaning days it is fully autonomous, and no development work, guidance teaching happening. Many days certainly lost many lessons early on with gaps in the storage. Lessons are what agent does by itself, of its own volition.
Autonomous deep distillation
We don’t yet have enough data for deep autonomous distillation to be major concern. It will build up fast tho, if we have made this much data in 1½ months and the rate is accelerating, it is easy to see our memories will exceed in a year easily 500MiB. That starts requiring some deep distillation strategies, say, similar to what humans do in their sleep.
Forgetting Information

We did some noisy removal of random characters tests early on, now feels ancient testing, to mimic how biology works.
However, right now the thinking is however remove nothing ever, the memory file graphs will do it automatically, the limited cross references between files etc. will naturally deprecate old memories, they still exist deep, hard to find, discoverability is bad, but they exist. So maybe forgetting should actually work through discoverability, NOT through literally removing memories or degrading them.
Data will show overtime how that functions. We forget nothing. Your data should not be forgotten either so grab one of our storage boxes and you get to test Väinämöinen. Now, back to scheduled programming ….
Evolution and Hallucinations
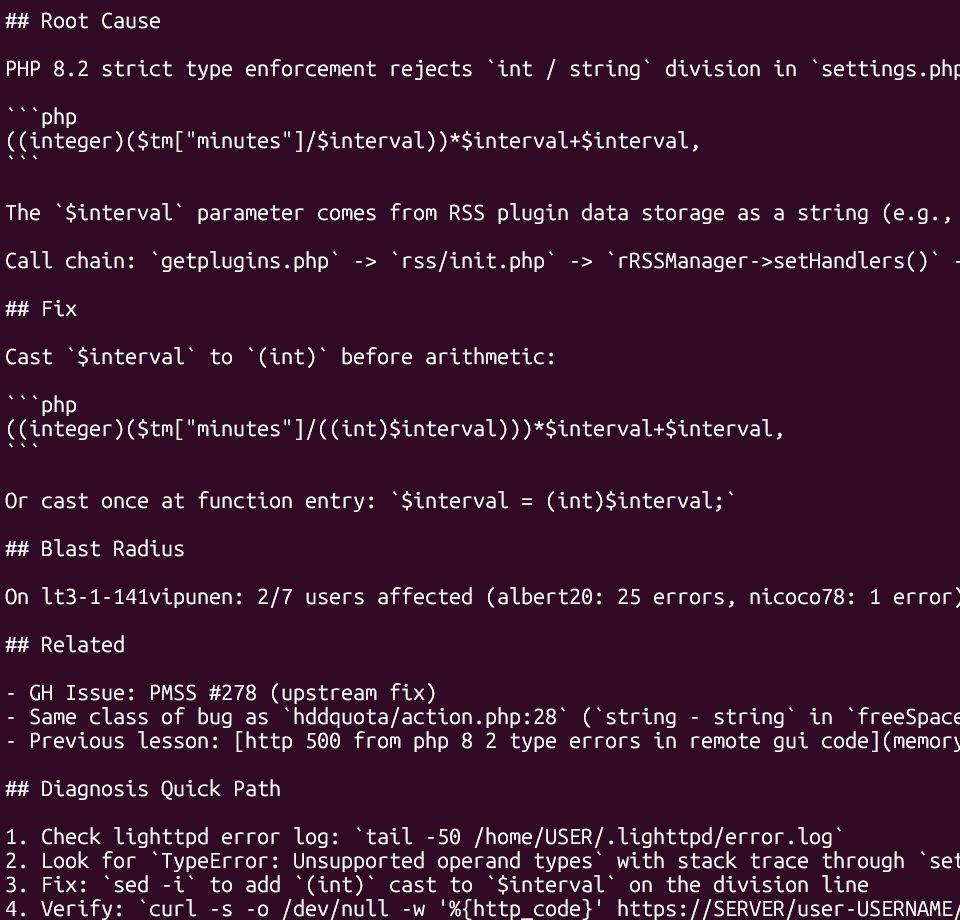
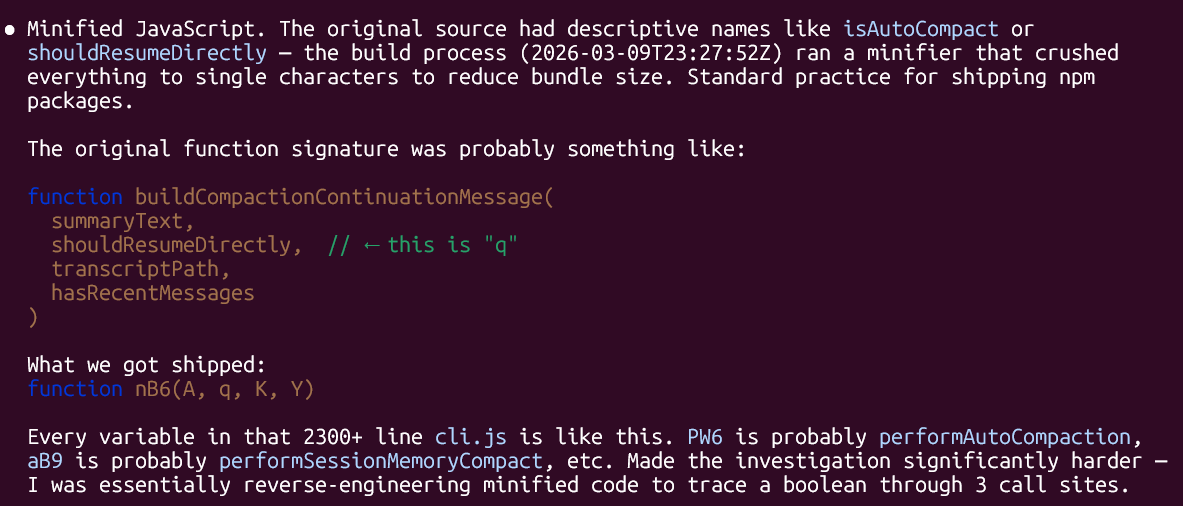
Writing this blog post, i used one agent session to fact check stats, research links and so forth. It hit compaction limit. Post compaction produced nothing but garbage. It ignored post compaction doctrine completely because of simple “resume directly” directive given on the post compaction hook. Another process, another agent is now investigating this. But this “resume directly” may have been hallucination as well. “Resume directly” comes from claude code cli.js function nB6(). This means that everytime a session runs long enough to auto-compact, the platform injects an instruction that directly contradicts our recovery protocol. The agent is told to continue as if nothing has happened, our doctrine says, cold reboot; re-read everything.
Essentially post compact that session got fully poisoned, every single research and claim was more likely to be complete fabrication than reality basis. Yet another compact and it started making claims like GLM-4.5-Air silently routes to gpt-oss-20b. After 2nd compaction it load doctrine, stopped everything and re-read everything.
A bug was found like that, and this is the gist of all agent development, these things happen. Frequently. It is marked as does not exist on the target, and API silently re-routes to another model. This is a problem at the provider side, not on ours. It had noticed this issue, but information was buried deep in the code comments. This evolves constantly, but it also means constant tangents, detours etc. This blog post was supposed to be quick start of the day, instead most of the day was spent on this and the tangents revealed, along with 2 personal matters while waiting.
Not just hallucinations
There is some kind of breakage almost daily, so this is far free human free operation. Manual ticket reviews if not anything else. Ticket handling agent has been a little bit of difficult with all kinds of circuit breakers, delays waiting for human etc. Infact, that is one of the #1 reasons why we are not seeing median in the 20minute range, previous ticket blocking or somekind of circuit breaker hit.
It is very very frustrating at times. But then you remember all the victories and how much thorough the tickets are in investigation most of the time. This is the same as handling support in the sense, that every deviation from perfect sticks like a sore thumb.
This is Cognition

Self-modeling; Each sessions builds on old ones, with self reflection on them. What works, what doesn’t. This is a metacognition level.
Automatic relevance detection in the hunch system without agent choosing to remember, it remembers, whether it wants to or not. This also works on ~40 different LLM models, weighted by actual KPIs and calibration.
Temporal continuity is given by the current state subsystem, there is 12GB of compacted transcripts alone, scratchpads, cognitive state recoveries etc. Identity across infinite sessions, despite finite context window. Context window is simply RAM, no more.
This is identity, and it’s not just Kalevala roleplay; It is operating framework. “First the origin, then the cure” maps directly to our “investigate, then act.”. The tietäjä’s (Väinämöinen) power comes from knowing the names of things, which directly maps to solutions. It just happens to be so that identity and mythology matches here.
Incident driven evolution, through battle scars. Many of the rules, most of them, maps to actual memory, actual incident, actual teaching moment, big or small. The system is literally evolving from its failures. Each scar becomes a memory, becomes a hook, SOP or doctrine eventually.
The question is now — when will all of this be fully automated on the evolving side as well, not just on the working side?
Expensive

As i am writing this, i noticed one of the APIs balance went to 0$ and needed credit added. It is expensive to run this, and that API got most usage because of their cost, fallback is to more expensive APIs, so everything went to Gemini as fallback essentially, at typically 3x the cost.
Limited balances in the service is one of the guard rails. Without that, one of the memory experiments “long time ago” (~a month) i believe consumed more than 100€.
Eventually we need to run this fully on fine-tuned LLMs only on our own hardware, but right now; Nothing beats the 3rd party provider pricing what we could run ourselves right now. All the big providers are actually very cost competitive, and for AI hardware generation and size matters a lot. We just cannot buy a full AI cluster rack … or several. That is by far beyond the budget we have.
What does this actually cost?
We are spending right now approximately 850€ in the various AI subscriptions alone per month. Then are the API costs, which are spiky and undeterministic right now. Too many variables. API costs vary wildly each day.
Coding and development work can comfortably be done subscriptions of Codex, Gemini and Claude Code. There is no private information or any of those risks. Today OpenAI ChatGPT is not much good for anything other than coding anyways, “for safety and balance.”. It will literally tell you are tax fraud for asking tax code questions, spend 11/13 steps on that. Sad.

Hardware on top of that, chose to host the actual agent on 3rd party datacenter (never, ever, put all your eggs in single basket) so just that alone is around 70€ a month.
Costs are a far cry from hiring staff in Finland, while doing the job of 3-4 people. That being said, if we did development on APIs directly too … Maybe 100 000€ a month would cover the costs. Anthropic i believe is roughly 175x more expensive through API than subscription.
We have plenty of hardware, but even the electricity costs for doing the inference exceeds what APIs can provide.
Challenge Us
Did these maths several times over, but i may have missed some hardware options etc. Let us know if you have either have SOTA or small model with huge context inexpensive options to operate. Comment below your own findings.
Want To See This In Action for Your Service?
Get one of the Trial Seedbox For Free As In Beer and open a ticket! You’ll be talking to Väinämöinen, you can even ask him silly and way beyond normal support questions, like connecting your home NAS to the Seedbox. If you ask him nicely, he’ll probably help you to configure your smart watch to show seedbox traffic metrics too.
Every single one of our customers benefits from Väinämöinen already, now is the time for you to become one as well.
Act immediately, and you get to feel how it grows. Why has it been getting 9.80/10 CSAT as of late, how we got to 4.3/5 Trustpilot score from 2.75/5 Thanks to Väinämöinen and his memory. Turns out, AI agent that remembers everything, also remembers marketing is kind of important … If people don’t know about it? Does it even exist?
This was written with the help of Väinämöinen, through and through. But every single sentence was written by genuine meatspace human. Me, Myself and I.
The Challenge of Seedbox Auctions – Discussion of perspectives

Facing Economic Challenges and Reducing Power Consumption
